Article Text

Abstract
Objective This study aimed to systematically evaluate published predictive models for dental caries in children and adolescents.
Design A systematic review and meta-analysis of observational studies.
Data sources Comprehensive searches were conducted in PubMed, Web of Science, Cochrane Library, Cumulative Index to Nursing and Allied Health Literature, Embase, China National Knowledge Infrastructure, Wanfang Database, China Science and Technology Journal Database (VIP) and SinoMed for relevant studies published up to 18 January 2024. The search focused on caries prediction models in children and adolescents.
Eligibility criteria Eligible studies included observational research (cohort, case–control and cross-sectional designs) that developed risk prediction models for dental caries in children and adolescents aged ≤18 years. Each model was required to include a minimum of two predictors. Studies were excluded if they were not available in English or Chinese, primarily focused on oral microbiome modelling, or lacked essential details regarding study design, model construction or statistical analyses.
Results A total of 11 studies were included in the review. All models demonstrated a high risk of bias, primarily due to inappropriate statistical methods and unclear applicability resulting from insufficiently detailed presentations of the models. Logistic regression, random forests and support vector machines were the most commonly employed methods. Frequently used predictors included fluoride toothpaste use and brushing frequency. Reported area under the curve (AUC) values ranged from 0.57 to 0.91. A combined predictive model incorporating six caries predictors achieved an AUC of 0.79 (95% CI: 0.73 to 0.84).
Conclusions Simplified predictive models for childhood caries showed moderate discriminatory performance but exhibited a high risk of bias, as assessed using the Prediction Model Risk of Bias Assessment Tool (PROBAST). Future research should adhere to PROBAST guidelines to minimise bias risk, focus on enhancing model quality, employ rigorous study designs and prioritise external validation to ensure reliable and generalisable clinical predictions.
PROSPERO registration number CRD42024523284.
- Child
- Health
- Machine Learning
- Meta-Analysis
Data availability statement
Data are available upon reasonable request.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
STRENGTHS AND LIMITATIONS OF THIS STUDY
This study systematically reviewed published predictive models for childhood caries, using the Prediction Model Risk of Bias Assessment Tool to assess both the risk of bias and the clinical applicability of these models.
A meta-analysis of six models demonstrated robust predictive performance, identifying differences in predictive factors, study characteristics and statistical methods as potential sources of heterogeneity across the included studies.
However, due to the limited number of studies available, it was not feasible to perform a meta-regression analysis to further explore the sources of heterogeneity.
The machine learning models included in this study involve complex algorithms and data processing procedures, which may challenge the capacity of bias assessment tools to comprehensively evaluate the risk of bias in predictive models.
Introduction
Dental caries is a complex disease influenced by a variety of factors, including clinical, microbiological, behavioural and social factors.1 The global prevalence of dental caries remains alarmingly high, ranking among the top 50 most common diseases with a prevalence rate of 35%. In 2010, the global prevalence of dental caries in primary teeth was reported at 9%, while in 2017, approximately 2.3 billion individuals worldwide were affected by permanent tooth caries, with an additional 500 million children experiencing caries in their primary teeth.2 The significant prevalence of dental caries in children underscores the impact of the disease on their overall quality of life.3 The detrimental impacts of dental caries on children encompass growth, development, nutritional challenges and quality of life concerns, as well as significant economic and social repercussions for families.4 A substantial proportion of children with caries present with severe dentine disease, necessitating dental surgical intervention.5 Nevertheless, the presence of early caries does not necessarily indicate active disease, underscoring the importance of assessing lesion activity to differentiate between children requiring dental intervention and those who do not. If left untreated, active enamel lesions can progress to the dentine, necessitating restorative treatment. Approximately 40% of untreated dentine lesions develop complications.6 Cavitary lesions involving the dentin may expose the pulp, requiring complex endodontic treatment or extraction.7 This can result in physical and psychological harm to the child and increased financial burden on the family. Tooth decay, while common, is preventable. Early diagnosis and preventive measures are crucial in controlling the progression of caries.
Numerous studies have investigated the primary causal factors and disease indicators of caries, a preventable oral health condition. These factors encompass caries experience, dental plaque, fluoride exposure, diet, salivary flow and overall health status.8 Caries risk assessment (CRA) is a clinical procedure used to ascertain the probability of an individual developing caries lesions in the immediate future, serving as a valuable tool for caries prevention and oral healthcare management.9 Currently, four widely used models for evaluating caries risk include ADA (American Dental Association), CAT (Caries-Risk Assessment Tool), CAMBRA (Caries Management by Risk Assessment) and Cariogram. The utilisation of assessment models in dental care necessitates the involvement of healthcare professionals and specialised tools. Escalating rates of dental caries and inadequate parental oversight pose challenges for children in low- and middle-income nations seeking access to dental services. The implementation of a straightforward and comprehensive caries assessment protocol can aid dental practitioners in identifying early caries risks and delivering timely preventive care. This review systematically examines simplified assessment models that do not rely on biological markers, as the concept of CRA remains a topic of debate among researchers. Several studies have indicated that environmental factors play a more significant role in determining the risk of caries compared with genetic factors. Within a genetic framework, certain factors may vary with age.10 Socio-economic status, psychosocial factors and early childhood behavioural patterns are relevant to the occurrence of dental caries and are more easily measurable.
The use of predictive models, particularly those incorporating machine learning (ML) techniques, is becoming increasingly prevalent in the medical field, with applications extending to the prediction of paediatric caries. While there is considerable enthusiasm about the potential of artificial intelligence (AI) to enhance caries prediction, experts have emphasised the importance of ongoing monitoring of model performance in a localised context to optimise long-term benefits.11 Despite the increasing risk of prediction models for dental caries in children, these models currently lack comprehensive evaluations regarding the quality, risk of bias and clinical applicability of relevant prediction models. The aim of this study was to screen and systematically review existing caries risk prediction models developed and published for children to inform the future construction of relevant models and clinical practice.
Methods
The study protocol was registered with PROSPERO (registration number: CRD42024523284). Since this study relied exclusively on previously published research, an ethical approval statement was not required.
Determine search strategy
To conduct a comprehensive literature search, Chinese and English databases were selected to account for the large population size and the diversity of languages spoken. The following databases were systematically searched: China National Knowledge Infrastructure, Wanfang Database, China Science and Technology Journal Database (VIP), SinoMed, PubMed, Web of Science, The Cochrane Library, Cumulative Index to Nursing and Allied Health Literature and Embase. A combination of subject headings and free-text terms was employed to ensure a comprehensive search. The retrieval timeframe spanned from the inception of each database to 18 January 2024. The Geersing updated search filters were used. These filters, developed by Geersing et al,12 represent an enhancement of the Ingui and Haynes filters, designed to improve both recall and accuracy in literature searches. The search strategy incorporated the following keywords: “stratification”, “diagnostic model”, “prediction model”, “dental caries”, “dental cavity”, “carious” and “child”. The detailed search strategy is provided in online supplemental table 1 for reference.
Supplemental material
To ensure the accurate retrieval of predictive model studies, Cochrane Prognostic Omics has introduced the PICOST framework (population; index prognostic factor or model; comparative factor or model; outcomes to be predicted; timing of the prediction horizon and of the moment of prognosis; setting). This framework builds on the established PICO structure (Population, Intervention, Comparator, Outcome) and is designed to enhance the construction of predictive models for systematic reviews.13
P (Population): The target population consists of children and adolescents (aged 1–18 years old).
I (Intervention model): Developed and published simple predictors for dental caries in children (predictor ≥2).
C (Comparator): Models without competing models.
O (Outcome): The results focused on simplifying the prediction model of dental caries in children, rather than incorporating other microbiological indicators.
T (Timing): The model is intended for use in asymptomatic children and can facilitate rapid detection of children with undiagnosed dental caries.
S (Setting): The model can help detect undiagnosed dental caries and implement preventive oral healthcare at home for asymptomatic children.
Furthermore, we employed the Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TPIPOD-SRMA) assessment14 and adhered to the CHARMS checklist.15 These tools facilitated the clear delineation of the review objectives, the development of a comprehensive search strategy and the establishment of precise inclusion and exclusion criteria for the studies.
Inclusion and exclusion criteria for study selection
The inclusion criteria for the studies were as follows: (1) studies involving children and adolescents with dental caries; (2) observational study designs; (3) reports including a predictive model; (4) the development or validation of a multivariate model aimed at predicting caries risk in children; and (5) the prediction model must incorporate at least two predictors.
The exclusion criteria were as follows: (1) studies that did not incorporate a predictive model; (2) studies focusing primarily on the oral microbiome; (3) studies not published in English or Chinese; and (4) studies with unclear or incomplete original text.
Study screening and data extraction
In the selected studies, two primary categories of information were extracted: (1) key characteristics, which encompassed details such as the authors, publication year, study design, participant demographics, data sources and sample size and (2) model information, which included specifics about the model itself, such as variable transformation methods, variable selection processes, model performance metrics (eg, discrimination and calibration), the predictors used and the validation techniques employed.
Two reviewers, XW and HL, independently conducted the initial screening of the studies. After removing duplicate studies, the remaining studies were evaluated based on their titles and abstracts, with non-eligible studies being excluded at this stage. Subsequently, the full texts of the remaining studies were reviewed in accordance with the predefined inclusion and exclusion criteria, and the reference lists of all eligible studies were examined for potentially relevant articles. In cases where disagreements arose regarding study selection, the issue was resolved through discussion among three authors (XW, HL and DY) until a consensus was reached.
Quality assessment
We assessed the risk of bias and suitability of the included studies using the Prediction Model Risk of Bias Assessment Tool (PROBAST),16 which assesses the quality and potential risk of bias in the selected studies. The tool comprises four domains with 20 signalling questions, each answered as ‘yes/probably yes’, ‘no/probably no’ and ‘no information’, and each domain is rated as ‘high risk’, ‘low risk’ and ‘unclear’ for overall risk of bias. A domain was classified as having a high risk of bias if at least one signalling question was answered ‘no’ or ‘probably no’, and the overall risk of bias was considered low only if all domains were rated as low risk. Besides, the applicability of the studies was assessed across three domains—study participants, predictors and outcomes—with each domain rated as ‘excellent’, ‘poor’ and ‘unclear’.
Data synthesis and statistical analysis
To summarise the prediction model of the forest plot, a meta-analysis of the area under the curve (AUC) values from the validation model was conducted using Stata (V. 15.0). Heterogeneity was assessed using both the I² statistic and the Cochrane Q test. The I² index, which quantifies heterogeneity, was interpreted at thresholds of 25%, 50% and 75%, representing low, medium and high levels of heterogeneity, respectively.17 Egger’s test18 was employed to evaluate potential publication bias, taking into account the heterogeneity observed in the analysed results.
Patient and public involvement
None.
Results
Study selection and study characteristics
The Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 flowchart, as illustrated in figure 1, outlines the systematic and detailed search process undertaken for this study. Initially, 4666 records were identified through comprehensive search efforts. After the removal of duplicates, 1934 titles and abstracts were screened for relevance. On a thorough review of these titles and abstracts, 41 documents were selected for full-text assessment. Following this in-depth evaluation, 11 articles met the inclusion criteria and were ultimately incorporated into the review study.

Preferred Reporting Items for Systematic Reviews and Meta-Analyses flowchart of literature search and selection.
Online supplemental table 2 outlines the key characteristics of the 11 studies (n=11) included in this analysis, all published between 2018 and 2023, with the following geographical distribution: China (n=5) (two studies published in Chinese); Korea (n=2); Brazil (n=2); Singapore (n=1); and Sri Lanka (n=1). The research methodologies employed in these studies primarily consisted of prospective cohort studies and cross-sectional surveys, complemented by two retrospective studies. The age range of participants spanned from 1 to 18 years, with studies focusing on caries in primary dentition (n=5), caries in young permanent teeth (n=5) and the cumulative prevalence of caries in both primary and permanent dentition (n=1). Cohort studies featured follow-up periods ranging from 3 months to 10 years, and sample sizes varied from 200 to 4573 participants. Many of the studies used the dmft (decayed, missing and filled primary teeth) and DMFT (decayed, missing and filled permanent teeth) indices as comprehensive measures for evaluating oral health outcomes.
Table 1 presents the characteristics of the included studies, which encompassed various types of ML algorithms, including Logistic Regression (n=10), Random Forest (n=4), Decision Tree (n=3), Extreme Gradient Boosting (n=3), Support Vector Machine (n=1), Multi-Layer Perceptron neural networks (n=1), Adaptive Boosting (n=1) and K-Nearest Neighbour (n=1). Numerous studies have developed these multiple ML models to facilitate performance comparisons. The models incorporated candidate predictors ranging from 38 to 9 in number.
Model characteristics in the literature included
Table 2 presents data on the performance metrics and predictors of the models discussed in the reviewed literature. Among the total papers reviewed, seven articles reported internal validation, with six using cross-validation and one employing bootstrap validation. One study conducted external validation without explicitly disclosing validation data or related information, while three studies did not provide any details regarding validation. The most common predictors identified across the models included the use of fluoride toothpaste and brushing frequency, which were featured in five models, followed by the frequency of sugar or snack consumption and nighttime toothbrushing after eating, which appeared in four and two models, respectively. Furthermore, parental awareness of childhood caries and the frequency of dental check-ups were noted as significant predictors. The reported model performance, as indicated by ROC or C-statistic values, ranged from 0.566 to 0.91.
Comparison of the performance of models from the literature
Results of quality assessment
The overall evaluation of bias risk, conducted using the PROBAST tool, is summarised in online supplemental table 3, summarising the bias risk and applicability of the studies included in the analysis. All studies were assessed as having a high risk of bias, primarily due to concerns related to the statistical analysis of data and unclear applicability stemming from insufficient clarity in the overall presentation of the models. Additional details regarding the reasons for bias and the limitations of the studies are provided in online supplemental table 4.
In the domain of study populations, three studies were identified as having a high risk of bias: one used data from a retrospective study,19 another from a non-nested case–control study20 and the third relied on a registry database but applied inappropriate exclusion criteria that may have inadvertently excluded children with caries.21 Besides, within the domain of predictor assessment, four studies failed to clearly report the definition and assessment methods for predictors,19 20 22 23 while one study potentially introduced bias by using outcome information during the collection of predictors.24 Furthermore, in the domain of outcome indicators, standard information was provided without explicit reference to how outcomes were defined in two studies,19 20 and one study may have used predictor information to determine the outcome, raising concerns about bias.24
All included studies in the area of statistical analyses were assessed to be at high risk of bias due to several methodological limitations. One study had events per variable (EPV) counts of less than 10,25 while four studies selected predictors based solely on univariate analysis.22 23 26 27 In one study, a continuous variable, birth weight, was inappropriately transformed into a categorical variable with only two categories.23 Two studies potentially failed to adequately assess calibration and discrimination,19 23 and one study relied exclusively on the Hosmer-Lemeshow goodness-of-fit test for calibration.20 Besides, three studies lacked internal validation,20 21 28 and one study exhibited a clear flaw in handling missing values.20 Furthermore, eight studies did not report any methods for addressing missing data,19 21–27 and two studies failed to account for the complexity of their data.24 29
In the context of risk assessment for applicability, five studies were identified as having a high risk, while the remaining six studies were deemed to have an unclear risk level. The five studies classified as high risk were primarily due to their focus on specific populations, which raised concerns about their fitness for purpose.19 22–24 27 The remaining studies were categorised as having an unclear risk of fitness for purpose, as the reporting of outcome measures was insufficiently detailed or ambiguous.20 21 25 26 28 29
Statistical methods of models
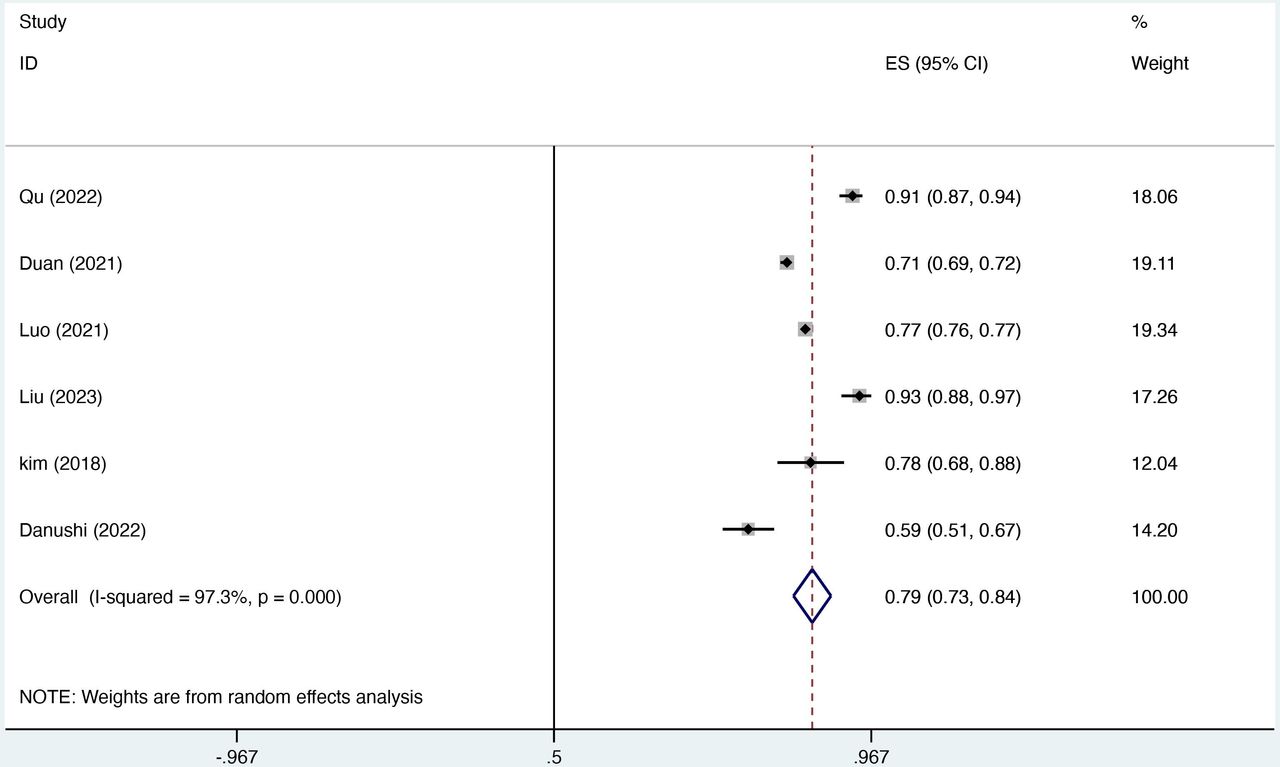
In figure 2, only six studies met the eligibility criteria for inclusion in the joint analysis, as the remaining studies lacked detailed reports on external validation of the model. The most effective model was selected for analysis, given that the included studies were derived from the same sample.25 In our study, the combined AUC, calculated using a random-effects model, was 0.79 (95% CI: 0.73 to 0.84). The I² value of 97.3% (p<0.001) showed a high degree of heterogeneity among the studies, while the Egger’s test value of 1.66 (p=0.68) suggested no significant publication bias.

{kind=link}
{kind=link}
Pooled area under the curve estimates from random-effects meta-analysis of six simple childhood caries prediction models.
Discussion
According to the PROBAST bias assessment checklist, all included studies were deemed to be at a high risk of bias, and their adaptability remained unclear. To enhance the robustness of model development, it is recommended to prioritise prospective study designs, as these collect data prior to the investigator’s observations, thereby improving data reliability and mitigating recall bias.30 Among the evaluated models, one was derived from a retrospective cohort study, which is susceptible to recall bias and may compromise data reliability. Another model was based on a case–control study, and the use of weighted data could be employed to enhance its accuracy.31 Furthermore, it is essential that all predictors within each study are clearly defined and assessed using rational methodologies to minimise variability and potential sources of bias.
In model construction, studies with an EPV below 10 are at risk of overfitting, and it is generally recommended to maintain an EPV of at least 20 to enhance model accuracy.32 Missing data represent a prevalent issue in clinical and medical research, and addressing this challenge is critical to ensuring reliable results. One study employed a questionnaire-based approach to impute missing data, which may introduce bias and affect model performance, while two other studies used multiple imputations. Multiple imputation was recommended as the most appropriate method for handling missing data, as it outperformed other methods in terms of bias and accuracy in model development and validation.33 Besides, three studies were found to have a high risk of bias due to their reliance on univariate analyses for predictor selection. This method fails to account for interactions between variables and the complex relationships between predictors and outcomes, potentially compromising model performance in real-world applications. To address this limitation, the use of multivariate analysis techniques is essential, as they incorporate these interactions and contribute to more robust and generalisable models.34
In this review encompassing 11 studies, the AUC of all the models for the constructed models ranged from 0.566 to 0.931, with the majority demonstrating excellent predictive performance. However, three studies were identified as having a high risk of bias due to insufficient calibration and discrimination. Calibration plots or tables are valuable tools that enhance transparency by visually highlighting calibration issues within specific probability ranges, thereby supporting comprehensive model evaluation and improvement. Both internal and external validation are critical to ensuring the optimal fit of predictive models. One study employed a 7:3 split for training and test datasets, along with k-fold cross-validation; however, this approach can lead to overfitting and optimistic performance estimates, particularly with small sample sizes, and varying random splits may yield inconsistent results. To enhance model reliability and mitigate bias, it is recommended to combine cross-validation and bootstrap methods with external validation across diverse populations and clinical settings, as this approach strengthens the robustness and generalisability of predictive models.35
The meta-analysis of the six models yielded a combined AUC of 0.79 (95% CI: 0.73 to 0.84); however, significant heterogeneity was observed among the models. This variability can be primarily attributed to differences in the analytical approaches used to construct the models, as well as disparities in the populations, predictors and methodologies employed. Our evaluation process also identified inconsistencies in adherence to the TRIPOD guidelines across some studies. To enhance transparency, readability and the effectiveness of peer review, we recommend that future studies use the TRIPOD report as a reference for the development, validation and refinement of predictive models.36 Besides, this review includes five ML-based models and the emerging TRIPOD-AI framework, designed specifically for evaluating ML models, can serve as a valuable resource for guiding the construction of future models.37
With the advancement of the digital and intelligent healthcare landscape, ML and AI models are increasingly being applied across various facets of healthcare, extending beyond their traditional roles in imaging and bioinformatics to areas such as clinical decision-making and nursing care. For instance, among the reviewed studies, five21 22 25 26 29 employed ML techniques to develop predictive models for childhood caries, using diverse methodologies for model construction. Tools such as RStudio and Python were frequently chosen for modelling, with approximately 36% of the studies comparing multiple ML algorithms for improved detection or prediction accuracy. Notably, the study by Toledo Reyes et al evaluated results based on dataset characteristics, extracted features and model complexity.38 Two variable selection methods were employed to contrast traditional models with ML techniques, with the latter using the Boruta algorithm for feature selection. The Boruta algorithm, known for its ability to handle multiple features, capture non-linear patterns and provide robust discriminative power, demonstrated advantages over classical statistical methods.39
The Shapley Additive Explanations (SHAP) approach enhances the interpretability of the model at both global and local levels, offering insights into the overall functioning of the model as well as personalised data for individual predictions.40 In this study, the SHAP algorithm was us to identify caries severity as the most influential predictor in the development of caries in deciduous dentition, while also identifying six key predictors in the permanent teeth prediction model. The researchers demonstrated methodological rigour by employing multiple imputations to effectively handle missing data. Moreover, they conducted a comprehensive evaluation of the model’s calibration and discriminative performance, while also clarifying the importance of various predictors within the model—aspects that are frequently neglected in other studies.
The predictive models discussed in this review hold significant clinical relevance, as they were developed using a combination of social, psychosocial, behavioural and clinical predictors. High-frequency predictors identified in these models, such as the use of fluoride toothpaste and the restriction of sugar consumption in children, are widely endorsed preventive strategies with important implications for nursing practice and clinical prevention.41 Enamel demineralisation, primarily caused by acid-producing bacteria from fermented carbohydrates, is exacerbated by frequent sugar consumption, which prolongs acid production and demineralisation. Fluoride plays a critical role in reducing dental caries globally by promoting remineralisation and counteracting acid-induced enamel damage.42 In the study conducted by Kalhan et al, mothers were followed from early pregnancy (<14 weeks of gestation) to 34 months postdelivery. The study findings suggested that early intervention for caries prevention in infancy is more impactful. Access to preventive oral health services through healthcare providers could decrease caries-related expenses for children by 32%. Mothers who received prenatal oral health education, treatment and screening from a multidisciplinary team, along with dental professional counselling, had children with a lower incidence of dental caries.43 Maternal education and economic status were identified as key predictive factors, with higher maternal education levels serving as a protective factor against dental caries, while lower education levels or illiteracy were associated with increased risk.44 However, the relationship between family income and childhood caries prevalence remains debated, though low household income and lower education levels are correlated with a higher risk of early childhood caries.45 The challenges faced by these families in accessing specialised health services, combined with their suboptimal nutritional status, limited opportunities for early diagnosis and poorer disease prognosis,46 may contribute to their increased reliance on public dental services, as highlighted in a study.47 In less economically developed countries, there is a pressing need for greater investment in public dental services to effectively address oral health disparities and ensure equitable access to care.
Strengths and limitations
The strengths of this systematic review and meta-analysis are noteworthy. To the best of our knowledge, this is the first study to comprehensively examine and detail research on caries prediction models for children, integrating six models and summarising their methodologies and predictive factors. This work aims to contribute valuable medical evidence to the field. However, several limitations should be acknowledged. First, the inclusion of literature in English and Chinese only may result in publication bias by omitting studies in other languages. Second, the included ML algorithm models involve complex algorithms and data processing processes, which may pose a risk of bias that cannot be adequately assessed by the PROBAST tool. Third, meta-regression was not performed due to the limited number of available studies. Fourth, differences in predictors, study characteristics, statistical analyses and selection of reports were potential sources of heterogeneity in the included studies. Finally, validation models were not assessed because of the lack of studies.
Conclusion
In this systematic review, 11 studies and 25 simplified models for predicting childhood caries were evaluated, with a pooled AUC of 0.79 (95% CI: 0.73 to 0.84) across six models, suggesting moderate discriminatory ability. However, all included studies were identified as having a high risk of bias according to the PROBAST assessment, raising concerns regarding the clinical applicability and predictive stability of these models. The findings underscore the importance of future research adhering to the PROBAST checklist and following the TRIPOD statement guidelines for model development and validation to enhance methodological rigour and reporting quality. In addition, external validation of these models should be prioritised to ensure their usability and generalisability in diverse clinical settings.
Data availability statement
Data are available upon reasonable request.
Ethics statements
Patient consent for publication
Ethics approval
Not applicable.
References
Footnotes
Contributors As the first author of this review, XW was responsible for overall project management, risk of bias assessment, analysis of evaluation results and writing the paper. XW and SQ contributed to the study conception and design. XW, XZ, HL, DL, DY and KL contributed to data acquisition or analysis and interpretation of data. XW, PZ, SQ, HZ and XZ were involved in drafting the manuscript or revising it critically for important intellectual content. All authors have given final approval for the version to be published. XW is responsible for the overall content as guarantor.
Funding The present study was supported by the Shenzhen Key Medical Discipline Construction Fund (No.SZXK039), the Longgang Medical Discipline Construction Fund (Key Medical Discipline in Longgang District) and the Longgang District Science and Technology Plan (No.LGKCYLWS2022003).
Competing interests None declared.
Patient and public involvement Patients and/or the public were not involved in the design, or conduct, or reporting, or dissemination plans of this research.
Provenance and peer review Not commissioned; externally peer reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.